Data Vault generator voor Informatica Powercenter
De Data Vault modelleringswijze is een gestandaardiseerde manier om een data warehouse te modelleren. Het biedt een aantal voordelen over andere wijzen zoals stermodellering.
Een veel gehoorde klacht is echter dat het veel werk is om alle benodigde ETL te bouwen. Voor elk Data Vault object dient namelijk een aparte laadstroom gebouwd te worden.
Het voordeel van de Data Vault laadstromen is dat ze allemaal op dezelfde manier werken en dus gegenereerd kunnen worden.
Nu ken ik een aantal generatoren voor verschillende ETL systemen (Oracle, SQL server, Java) maar bij mijn weten was er geen generator voor Informatica Powercenter. Daarom heb ik zelf een generator gebouwd waarmee Powercenter mappings en workflows gegenereerd kunnen worden op basis van metadata die in de Powercenter repository opgeslagen is.
Hieronder beschrijf ik hoe de generator werkt en benoem ik de voor- en nadelen van deze oplossing.
Normale laadstrategie
Dit is de standaard manier om een Data Vault te laden.
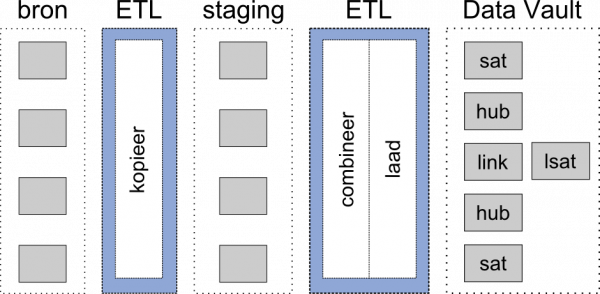
In bovenstaande afbeelding staat een normale laadstrategie voor het laden van data in een Data Vault data warehouse.
Over het algemeen wordt een kopie gemaakt van de brontabellen in een staginglaag (ETL 1). Daarna wordt data gecombineerd en geladen in de Data Vault (ETL 2). In dit proces zijn de kopieer- en laadprocessen standaard maar omdat het laadproces met het combineerproces samengevoegd zijn, is het lastig te genereren.
Daarom splits ik deze twee processen en wordt het mogelijk om het laadproces ook te genereren.
Nieuwe laadstrategie
Dit is de manier waarop ik data in de Data Vault laad.

In bovenstaande strategie is een pré Data Vault laag toegevoegd. In deze laag is alle brondata gecombineerd zodat er geen business logica in de Data Vault mappingen meer nodig is.
Kenmerken van de pré Data Vault laag
Dit zijn enkele kenmerken van de pré Data Vault laag:
- Fysiek of views
De laag kan bestaan uit fysieke tabellen of views op bestaande tabellen. - Bevat metadata
In de pré Data Vault laag ligt alle metadata vast die nodig is om de Data Vault mappings en workflows te genereren. - Tabellen bevatten één (voor hubs) of meerdere (voor links) business keys
- Één tabel per hub/sat combinatie
Door het aantal hubs per tabel te beperken tot één, weet de generator bij welke hub de satellite data hoort. Per tabel kunnen meerdere satellites gegenereerd worden. - Één tabel per link/lsat combinatie
Door het aantal links per tabel te beperken tot één, weet de generator bij welke link de satellite data hoort. Per tabel kunnen meerdere satellites gegenereerd worden. - Vluchtig
De data in de tabellen is alleen nodig voor het laden van de Data Vault. De tabellen kunnen leeggemaakt worden voor het laden. Ze kunnen dus ook leeggemaakt worden na het laden. - Controleerbaar
Alle data in de pré Data Vault laag kan eenvoudig gecontroleerd worden voordat het laadproces gestart wordt. Hierdoor kan bijvoorbeeld voorkomen worden dat er er geprobeerd wordt om dubbele business keys te laden. Deze (en andere) controle kan ook gegenereerd worden.
Kenmerken van de generator
Dit zijn enkele kenmerken van de generator:
- Flexibel
De generator gebruikt standaard powercenter exports waar extra generator tags aan toe gevoegd zijn. Hierdoor kan de generator mappings genereren zoals ze bij de opdrachtgever gebruikt worden. - Metadata uit de Powercenter repository
De metadata voor de generator staat opgeslagen in de Powercenter repository bij de source definities van de pré Data Vault laag. - Eenvoudige regels
De regels voor de tabelstructuur in de pré Data Vault laag zijn eenvoudig en voor alle analisten toe te passen. Hierdoor kunnen uitbreidingen snel gerealiseerd worden.
Voor- en nadelen
Het grootste nadeel van deze oplossing is dat er een extra laag geïntroduceerd wordt. Extra tabellen verhoogt de beheerlast aan de database- en modelleringskant. Daar bovenop moeten er soms extra tabellen gemaakt worden omdat de generator die nodig heeft. Zonder de generator zouden er bijvoorbeeld twee hubs geladen kunnen worden uit één tabel. De generator heeft echter een aparte tabel per hub nodig.
Deze nadelen wegen echter niet op tegen de voordelen van de generator:
- Tijdbesparing
Het spreekt voor zich dat het genereren van mappings vele malen sneller gaat dan het met de hand bouwen. Business logica gescheiden van Data Vault laadstromen In de pré Data Vault tabellen komt alleen functioneel relevante data. De technische overhead van de Data Vault tabellen wordt later automatisch toegevoegd. De mappings die de pré Data Vault tabellen vullen, kunnen hierdoor redelijk simpel blijven. - Foutloos
Als één mapping werkt, werken alle overige mappings ook. Nooit meer fouten omdat iemand één lijntje vergeten is te trekken in een mapping. - Betere laadstromen
De hoeveelheid werk van extra veiligheidsmechanismen kan nooit meer een exuus zijn om iets niet te doen. Omdat alle mappings gegenereerd worden, is het bijvoorbeeld heel eenvoudig om mappings te genereren die hubs vullen op basis van business keys die in links gebruikt worden. Hierdoor wordt vookomen dat een link niet gemaakt kan worden omdat de bijbehorende hub data niet gevonden kan worden. - Eenvoudig testen
Tijdens het testen hoeft alleen gekeken te worden of de data in de pré Data Vault tabellen goed is. Alles wat daarna komt, hoeft alleen getest te worden na het opleveren van de templates.